
はじめに
B+木とも呼ばれ、データベースの世界でよく聞く本用語ですが「B-Tree+とは何か?」と聞かれると答えに困る方もいると思います。というわけで、本用語を初めて聞いた方向けにデータベース関連の基礎知識を交えながら同用語の意味について分かりやすく解説しました。
B-Tree+/インデックスとは?
B+木を簡潔に言えば「データベースの中で採用されている多分木型のインデックス」です。
まずは話の前提である「インデックス」の部分を説明します。
インデックスとは本の世界における”索引”にあたる機能で、フルスキャンをせずにデータの探索をするためにテーブル毎に作成されます。データベースを設計したことがある方であれば、インデックスをどのように作成したこともあるかと思います。
そんなインデックスですが、具体的な利用方法として以下の例が分かりやすいです。要は「検索するキー」を全てのデータからしらみつぶしに読む(=全検索する)のではなく、事前に整理された階層構造に沿って値の探索を行うことで「効率よくデータを探索」できていることが分かります。
上の図は枝分かれが二本で分岐しているので「二分木」と呼び、B-Tree+は二つ以上に枝分かれをさせるため「多分木」となります。
B-Tree+の中身
ここからはB-Tree+の具体的なデータ構造ですが、ルートブロック、ブランチブロック、リーフブロックと呼ばれる3つのブロックによって構成されます。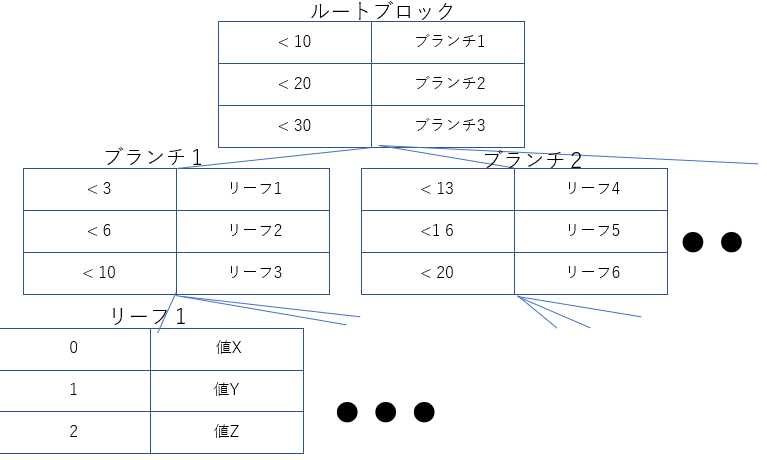
上で挙げた二分木と同じで探索を行う上ではルートブロックと呼ばれる頂点に位置するブロックから辿っていきますが、B-Tree+の特徴として「末端(リーフブロック)でのみ値を管理する」というものがあります。
なぜリーフブロックでしか値を持たないのか?
いくつかメリットがありますが、その中の一つである「広範囲に跨った検索に強みがある」点で説明します。
例えば特定のキーでの全文一致の検索ではなく、不等号を利用した検索の場面を考えてみてください。
B-Tree+ではリーフブロックにのみ値が格納されていないため、単純な条件分岐によってどんどん下の階層に掘っていくことが可能です。一方でB-Treeのようにブランチにも値が格納されている場合は分岐で絞り込む前に「ブランチで保持されている値を確認する」と言う照会操作が発生するため、このロジックを排除するためにRDBMではB-Tree+と言う機構が生まれました。
逆にブランチでも値を保持する”B-Tree”にも優位性はあり、条件分岐ではなく特定キーの探索においてはB-Tree+より効率的に行うことができます。デフォルトでB-Tree+が採用されているケースが多いのであまり気にする必要がないとは思いますが、検索条件の主な使われ方によってどちらを採用するのかを判断していくことも可能です。
終わりに
データベースだけでなくファイルシステムのインデックスにも採用されるB-Tree+ですが、ポイントは「多分木で末端でのみ値を管理する」という構造です。ここを抑えていると、書籍で本用語を見つけた場合も頭に入ってくるので覚えておくことをおススメします。