
はじめに
ECSのサービスにてTaskを1つだけ稼働させ、そのTaskを異常終了させた際にどの程度の時間でECSが別のTaskを復旧させるのかを実機を用いて検証を行いました。
尚、構成としてはALBを経由してECSのサービス(Apacheをコンテナとして起動)に割り振りを行う構成で、ALB経由で通信を断続的に行うことで業務通信を想定して応答結果を整理しています。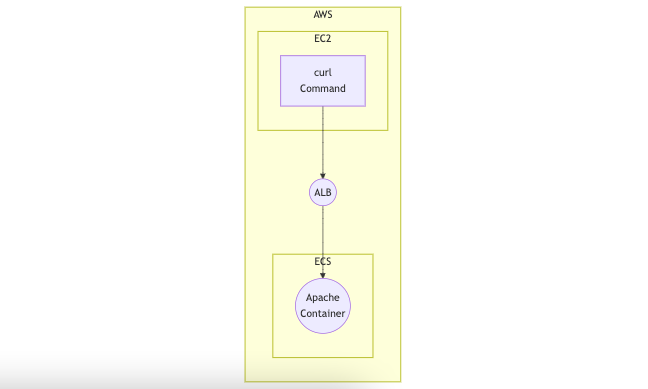
環境情報
- ECS Fargate 1.4
- aws-cli/2.15.5
障害の再現と計測対象
ECSのタスクの中に入り、EntryPointで指定したコマンドをkillします。
$ aws ecs execute-command --cluster xx --task xx --container apache --interactive --command "sh"
$ kill 9
その際にcurlの応答結果と、ECS Clusterより取得したコンテナの稼働数(runningCountとpendingCount)を以下コマンドから取得します。
検証結果/考察
| 経過秒 | イベント |
|---|---|
| 0s | ECSのタスクを異常終了させる |
| 0s | curlコマンドへのレスポンスが200→500番台になる |
| 10s | runningCountが1→0になる |
| 90s | pendingCountが0→1になる |
| 138s | runningCountが0→1, pendingCountが1→0になる |
| 143s | curlコマンドへのレスポンスが500番台→200になる |
コンテナの異常終了後、約1分後にコンテナの起動が開始して約2分程度で新たなコンテナが起動することを確認。尚、この時間は別で検証したコンテナの再起動の時間とも概ね合致していました。
今回はコンテナが異常終了することでALBが後続に割り振りができない状態となり、2分程度全ての通信がエラー応答となります。ただし、サービスとして二つのTaskを稼働させている場合は活きているコンテナがいるため、ALBのヘルスチェックによる切り離しが完了次第エラーは止まります。
終わりに
Kubernetesと比較すると自動復旧に時間がかかるので、タスクを1つでサービスを稼働させる場合は数分のシステムダウンを許容する必要があると感じました。
以上、ご参考になれば幸いです。